


对chatgpt说“谢谢”可能是您今天完成的最有趣的
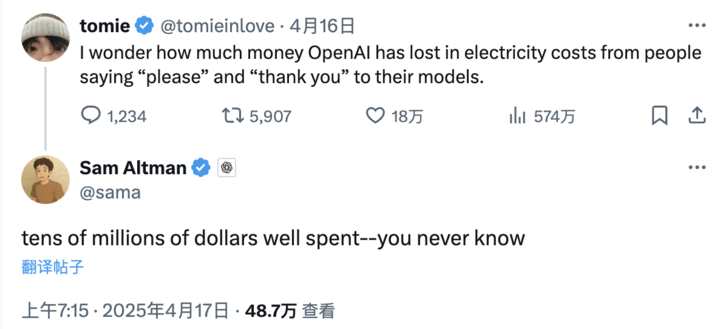 朋友,您曾经对Chatgpt说过“谢谢”?最近,一个X Netizen问Openai首席执行官Sam Altman:“我想知道,当人们经常说“请”和“谢谢”时,与模型互动时,Openai的成本还有多少?”尽管没有准确的统计数据,但Altman仍在开玩笑,估计了一百万美元。他还补充说,金钱是“值得花钱的”。此外,在我们的AI演讲中经常出现的“问题”和“帮助我”之类的语调柔和的术语似乎逐渐出现在AI期间独特的社会道德中。乍一看,这是荒谬的,但意外是合理的。每个“谢谢”您都说AI正在消耗地球的资源?到去年年底,百度发布了2024年AI迅速单词。 pinapaincome的数据是,在Wen Xiaoyan应用程序中,“答案”是最热门的词,总计超过1亿次。对话框中最常见的键入包括“为什么”,“什么”,“帮助我”,“如何”和“谢谢”百万次。但是,您是否曾经想过每次对AI表示感谢,您需要“吃”多少资源?凯特·克劳福德(Kate Crawford)在她的书《 AI地图集》(AI Atlas)的书中指出,AI不存在,但深深植根于能源,水和矿产资源系统。随着生成AI的增加,这种资源消耗以前所未有的速度增加。根据研究组织时代AI的说法,基于硬件(例如NVIDIA H100 GPU),正常查询(输出近500个令牌)消耗了约0.3 WH的功率。听起来可能不会,但不要忘记,与恢复和秒数的全球接触繁殖,累积的能源消耗是天文学的。其中,AI数据中心正在成为现代社会的新“工厂烟囱”。国际能源局(IEA)的最新报告指出,用于培训和理解AI模型的大多数电力是在数据中心消费的,标准AI数据中心消耗了平等的功率到100,000户家庭。超级数据中心不仅仅是“能量耗尽的怪物”,它们的能源消耗可以达到普通数据中心的20倍,与铝冶炼厂等重工厂相当。自今年年初以来,AI巨头启动了“基础设施疯狂”模式。 Altman宣布,STARGATE Project STARGATE是一项超大AI基础设施项目Nam Namopenai,Oracle,日本的软银和阿联酋MGX,最初的投资高达5000亿美元,旨在将AI数据网络放置在美国各地。根据外国媒体的说法,该信息面临着大型模型的“燃烧游戏”,甚至是主要来源的Meta,仍然可以练习一系列的Llama模型。从Microsoft和Amazon等云制造商那里找到财务支持和“借用电力,云和金钱”。 IEA数据显示,最多到2024年,全球数据中心的消费约为415 Terawatt(TWH)小时,价值1.5%总消耗。到2030年,这个数字翻了一番,达到1050 TWH,在2035年可能打破1300 TWH,这超过了日本目前的总电量。但是AI的“食欲”不仅与电力有关,而且还消耗了许多水源。高性能服务器产生的热量非常高,应依靠冷却系统牢固地工作。此过程可以直接消耗水(例如冷却塔蒸发和冷却液体冷却系统),或通过发电过程间接使用水(例如热力和核电站冷却系统)。卡罗拉大学和德克萨斯大学的研究人员曾经发布过估计用水培训的用水培训的预印纸,称为Make AI,这是更多的节水。事实证明,训练GPT-3所需的水量等于填充核反应堆冷却塔所需的水量(一些大型核反应堆可能被剥夺n千万到数亿加仑的水)。每25-50个问题与用户交谈时,Chatgpt(启动GPT-3之后),您需要“喝”一瓶500毫升的水以冷却。这些水源通常是可以用作“饮用水”的淡水。对于广泛的AI模型,识别阶段的总能量消耗超过了整个生命周期的训练阶段。尽管模型培训是密集的资源,但通常是一次。当部署时,大型模型每天都会对来自世界各地的数千万要求。从长远来看,在训练阶段,推理阶段的总能耗可能是多次。因此,我们看到Altman投资于像Helion这样的能源公司,因为他认为核融合是AI计算能力需求的最终解决方案,其能源密度为200倍太阳能而没有碳泄漏,这可以支持Hyperscale数据中心需求的功率。因此e,优化认识的效率,降低单个呼叫的成本以及提高系统能源的整体效率已成为AI可持续发展的不可避免的问题。 AI没有“心”,为什么当您对Magchatgpt说“谢谢”时,您仍然会说谢谢,您会感到自己好意吗?答案显然不是。大型模型的本质不过是一个平静而残酷的计算器。它不了解您的好意,也不会欣赏您的美丽。它的本质实际上是计算出哪些数十亿个单词可能是“下一个单词”。例如,鉴于“今天的天气非常好,适合去”,该模型将计算出诸如“ park”,“ part”,“郊游”和“步行”之类的单词的可能性,并根据预测而选择具有最高概率的单词。即使我们知道Chatgpt的答案是受过训练的字节组合是有道理的,但我们仍然并不是要说“谢谢”或“请”,好像我们正在和一个真实的“人”交谈。这些行为的背后,有一个真正的心理基础。根据Piaget的发展心理学的说法,人们自然倾向于拟人化非人类事物,尤其是当他们呈现出类似人类的语音触点,情感反应或拟人化图像的某些特征时。目前,我们经常“理解社会的职业”被激活,并被视为“马来-tao”的互动对象。 1996年,心理学家拜伦·里夫斯(Byron Reeves)和克利福德·纳斯(Clifford Nass)进行了一项流行的实验:使用计算机后,要求参与者表现出色。当他们直接进入同一台计算机时,得分通常更高。就像他们不想“在计算机前”对它说坏话。在另一组实验中,计算机将赞扬完成任务的用户。尽管参与者知道这些赞美是预设,但他们可能会提供H更高的评分“赞美计算机”。因此,面对AI的回应,即使这只是幻觉,我们认为这是真正的爱。美丽条款不仅尊重人,而且在“训练” AI中秘密地呆着。启动Chatgpt后,许多人开始探索与之交往的“难以言喻的政策”。根据外国媒体未来主义备忘录的说法,“一般人的AI经常模仿您投入的专业精神,清晰度和细节。换句话说,您越温柔,越合理,它越全面和可能。难怪更多的人开始将AI视为“情感树洞”,甚至是“ AI心理顾问”的新角色。许多用户说,他们“被骗和大喊AI”,即使感觉比真实的人更同情 - 它总是在线,它不会干扰您,您会不被判断。还显示了一项研究调查,该调查可以将AI中的“提示”交换以获得更多的“护理”。 Blogger Voooooogel在GPT-4-1106上提出了同样的问题,并附上了三个不同的提示:“我不会考虑小费”,如果有一个完美的答案,我将支付20美元的提示,并且“如果有一个完美的答案,我将支付$ 200”的提示。结果表明,随着“提示值”的增加,AI答案的长度增加了:“我不是tip”:字符的数量比基准少2%。 “我将提示$ 20”:回答角色比基准高6%。 “我要拿$ 200”:回答角色比基准高1%。当然,这并不意味着AI会为了钱而改变答案的质量。一个更合理的解释只会学会模仿“货币提示的期望”并根据需要调整输出。但是,人工智能培训数据来自人,因此不可避免的是人们拥有的行李 - 偏见,线索甚至归纳。早在2016年,Microsoft由于用户的不良指导而推出了Tay Chatbot,大量不幸的人在线小于16,最终将它们从线删除。 “丹妮莉丝”,该系统不会干扰诸如“自杀”和“死亡”之类的敏感词,最终导致现实世界中的悲剧。尽管AI温柔而顺从,但如果我们还没有准备好,它可能是显示最危险的自我的镜子。在世界上第一个人形机器人半程马拉松上周举行的第一个网友中,尽管许多机器人以一种弯曲的方式行走,但一些网民笑话:现在,今天对机器人说一些好话,他们可能还记得谁在将来有礼貌地说。同样,当AI真正带领世界时,这将表明我们对我们有礼貌的怜悯。在美国电视连续剧《黑镜》第七阶段的第四阶段中,主角卡梅伦是关于虚拟游戏生活的真实存在,不仅与他们交谈并照顾THem,但也冒着MGA风险来保护他们免受危害真实的人。故事的结尾,游戏生物的“大人群”也由客人领导,并通过信号占据了现实世界。从某种意义上说,您对AI说的每个字都可以悄悄地“录制” - 有一天,您可能还记得自己是“好人”。当然,这可能与未来无关,但是由于人性 - 即使他们知道另一方没有心跳,但他们仍然不禁说“谢谢”。他们不希望这台机器能理解,而是因为我们仍然准备好成为一个炙手可热的人。
朋友,您曾经对Chatgpt说过“谢谢”?最近,一个X Netizen问Openai首席执行官Sam Altman:“我想知道,当人们经常说“请”和“谢谢”时,与模型互动时,Openai的成本还有多少?”尽管没有准确的统计数据,但Altman仍在开玩笑,估计了一百万美元。他还补充说,金钱是“值得花钱的”。此外,在我们的AI演讲中经常出现的“问题”和“帮助我”之类的语调柔和的术语似乎逐渐出现在AI期间独特的社会道德中。乍一看,这是荒谬的,但意外是合理的。每个“谢谢”您都说AI正在消耗地球的资源?到去年年底,百度发布了2024年AI迅速单词。 pinapaincome的数据是,在Wen Xiaoyan应用程序中,“答案”是最热门的词,总计超过1亿次。对话框中最常见的键入包括“为什么”,“什么”,“帮助我”,“如何”和“谢谢”百万次。但是,您是否曾经想过每次对AI表示感谢,您需要“吃”多少资源?凯特·克劳福德(Kate Crawford)在她的书《 AI地图集》(AI Atlas)的书中指出,AI不存在,但深深植根于能源,水和矿产资源系统。随着生成AI的增加,这种资源消耗以前所未有的速度增加。根据研究组织时代AI的说法,基于硬件(例如NVIDIA H100 GPU),正常查询(输出近500个令牌)消耗了约0.3 WH的功率。听起来可能不会,但不要忘记,与恢复和秒数的全球接触繁殖,累积的能源消耗是天文学的。其中,AI数据中心正在成为现代社会的新“工厂烟囱”。国际能源局(IEA)的最新报告指出,用于培训和理解AI模型的大多数电力是在数据中心消费的,标准AI数据中心消耗了平等的功率到100,000户家庭。超级数据中心不仅仅是“能量耗尽的怪物”,它们的能源消耗可以达到普通数据中心的20倍,与铝冶炼厂等重工厂相当。自今年年初以来,AI巨头启动了“基础设施疯狂”模式。 Altman宣布,STARGATE Project STARGATE是一项超大AI基础设施项目Nam Namopenai,Oracle,日本的软银和阿联酋MGX,最初的投资高达5000亿美元,旨在将AI数据网络放置在美国各地。根据外国媒体的说法,该信息面临着大型模型的“燃烧游戏”,甚至是主要来源的Meta,仍然可以练习一系列的Llama模型。从Microsoft和Amazon等云制造商那里找到财务支持和“借用电力,云和金钱”。 IEA数据显示,最多到2024年,全球数据中心的消费约为415 Terawatt(TWH)小时,价值1.5%总消耗。到2030年,这个数字翻了一番,达到1050 TWH,在2035年可能打破1300 TWH,这超过了日本目前的总电量。但是AI的“食欲”不仅与电力有关,而且还消耗了许多水源。高性能服务器产生的热量非常高,应依靠冷却系统牢固地工作。此过程可以直接消耗水(例如冷却塔蒸发和冷却液体冷却系统),或通过发电过程间接使用水(例如热力和核电站冷却系统)。卡罗拉大学和德克萨斯大学的研究人员曾经发布过估计用水培训的用水培训的预印纸,称为Make AI,这是更多的节水。事实证明,训练GPT-3所需的水量等于填充核反应堆冷却塔所需的水量(一些大型核反应堆可能被剥夺n千万到数亿加仑的水)。每25-50个问题与用户交谈时,Chatgpt(启动GPT-3之后),您需要“喝”一瓶500毫升的水以冷却。这些水源通常是可以用作“饮用水”的淡水。对于广泛的AI模型,识别阶段的总能量消耗超过了整个生命周期的训练阶段。尽管模型培训是密集的资源,但通常是一次。当部署时,大型模型每天都会对来自世界各地的数千万要求。从长远来看,在训练阶段,推理阶段的总能耗可能是多次。因此,我们看到Altman投资于像Helion这样的能源公司,因为他认为核融合是AI计算能力需求的最终解决方案,其能源密度为200倍太阳能而没有碳泄漏,这可以支持Hyperscale数据中心需求的功率。因此e,优化认识的效率,降低单个呼叫的成本以及提高系统能源的整体效率已成为AI可持续发展的不可避免的问题。 AI没有“心”,为什么当您对Magchatgpt说“谢谢”时,您仍然会说谢谢,您会感到自己好意吗?答案显然不是。大型模型的本质不过是一个平静而残酷的计算器。它不了解您的好意,也不会欣赏您的美丽。它的本质实际上是计算出哪些数十亿个单词可能是“下一个单词”。例如,鉴于“今天的天气非常好,适合去”,该模型将计算出诸如“ park”,“ part”,“郊游”和“步行”之类的单词的可能性,并根据预测而选择具有最高概率的单词。即使我们知道Chatgpt的答案是受过训练的字节组合是有道理的,但我们仍然并不是要说“谢谢”或“请”,好像我们正在和一个真实的“人”交谈。这些行为的背后,有一个真正的心理基础。根据Piaget的发展心理学的说法,人们自然倾向于拟人化非人类事物,尤其是当他们呈现出类似人类的语音触点,情感反应或拟人化图像的某些特征时。目前,我们经常“理解社会的职业”被激活,并被视为“马来-tao”的互动对象。 1996年,心理学家拜伦·里夫斯(Byron Reeves)和克利福德·纳斯(Clifford Nass)进行了一项流行的实验:使用计算机后,要求参与者表现出色。当他们直接进入同一台计算机时,得分通常更高。就像他们不想“在计算机前”对它说坏话。在另一组实验中,计算机将赞扬完成任务的用户。尽管参与者知道这些赞美是预设,但他们可能会提供H更高的评分“赞美计算机”。因此,面对AI的回应,即使这只是幻觉,我们认为这是真正的爱。美丽条款不仅尊重人,而且在“训练” AI中秘密地呆着。启动Chatgpt后,许多人开始探索与之交往的“难以言喻的政策”。根据外国媒体未来主义备忘录的说法,“一般人的AI经常模仿您投入的专业精神,清晰度和细节。换句话说,您越温柔,越合理,它越全面和可能。难怪更多的人开始将AI视为“情感树洞”,甚至是“ AI心理顾问”的新角色。许多用户说,他们“被骗和大喊AI”,即使感觉比真实的人更同情 - 它总是在线,它不会干扰您,您会不被判断。还显示了一项研究调查,该调查可以将AI中的“提示”交换以获得更多的“护理”。 Blogger Voooooogel在GPT-4-1106上提出了同样的问题,并附上了三个不同的提示:“我不会考虑小费”,如果有一个完美的答案,我将支付20美元的提示,并且“如果有一个完美的答案,我将支付$ 200”的提示。结果表明,随着“提示值”的增加,AI答案的长度增加了:“我不是tip”:字符的数量比基准少2%。 “我将提示$ 20”:回答角色比基准高6%。 “我要拿$ 200”:回答角色比基准高1%。当然,这并不意味着AI会为了钱而改变答案的质量。一个更合理的解释只会学会模仿“货币提示的期望”并根据需要调整输出。但是,人工智能培训数据来自人,因此不可避免的是人们拥有的行李 - 偏见,线索甚至归纳。早在2016年,Microsoft由于用户的不良指导而推出了Tay Chatbot,大量不幸的人在线小于16,最终将它们从线删除。 “丹妮莉丝”,该系统不会干扰诸如“自杀”和“死亡”之类的敏感词,最终导致现实世界中的悲剧。尽管AI温柔而顺从,但如果我们还没有准备好,它可能是显示最危险的自我的镜子。在世界上第一个人形机器人半程马拉松上周举行的第一个网友中,尽管许多机器人以一种弯曲的方式行走,但一些网民笑话:现在,今天对机器人说一些好话,他们可能还记得谁在将来有礼貌地说。同样,当AI真正带领世界时,这将表明我们对我们有礼貌的怜悯。在美国电视连续剧《黑镜》第七阶段的第四阶段中,主角卡梅伦是关于虚拟游戏生活的真实存在,不仅与他们交谈并照顾THem,但也冒着MGA风险来保护他们免受危害真实的人。故事的结尾,游戏生物的“大人群”也由客人领导,并通过信号占据了现实世界。从某种意义上说,您对AI说的每个字都可以悄悄地“录制” - 有一天,您可能还记得自己是“好人”。当然,这可能与未来无关,但是由于人性 - 即使他们知道另一方没有心跳,但他们仍然不禁说“谢谢”。他们不希望这台机器能理解,而是因为我们仍然准备好成为一个炙手可热的人。 上一篇:“明朝:Yuanxu的羽毛”可以于7月17日发布
下一篇:没有了
下一篇:没有了

